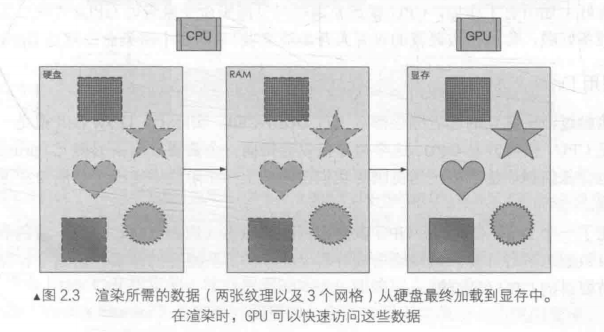
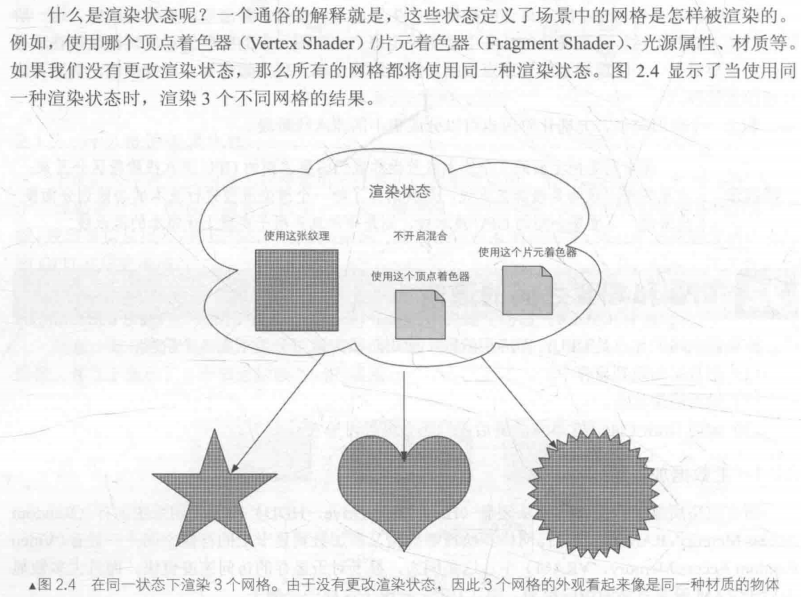
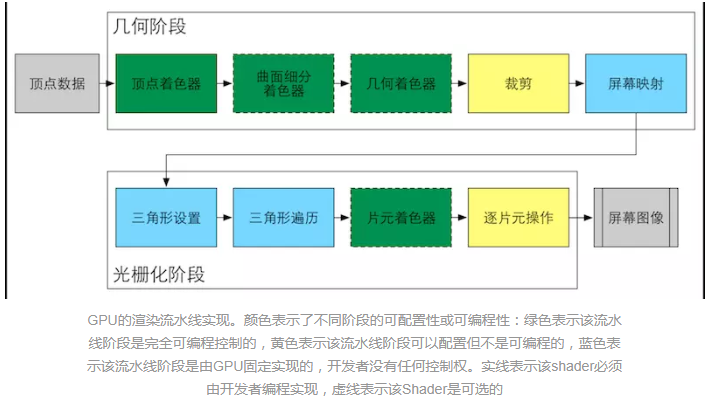
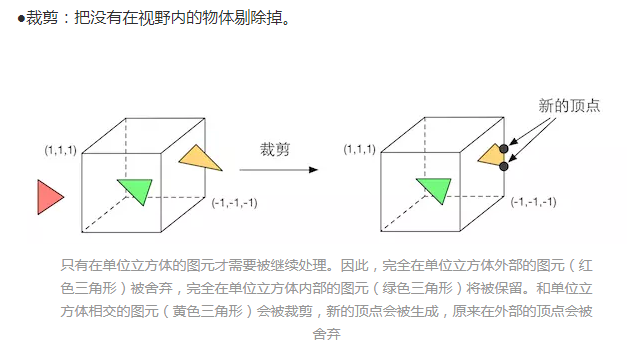
在计算机图形学领域,若要求取照明和投影的波动角度与反射效果,就常需计算平方根倒数。而浮点求平方根倒数运算带来的耗费巨大。

起源
此算法最早被认为是由约翰·卡马克所发明,但后来的调查显示,该算法在这之前就于计算机图形学的硬件与软件领域有所应用,如SGI和3dfx就曾在产品中应用此算法。而就现在所知,此算法最早由加里·塔罗利(Gary Tarolli)在SGI Indigo的开发中使用。虽说随后的相关研究也提出了一些可能的来源,但至今为止仍未能确切知晓算法中所使用的特殊常数的起源。
下列代码是《雷神之锤III竞技场》源代码中平方根倒数速算法之实例。示例去除了C预处理器的指令,但附上了原有的注释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
要理解这段代码,首先需了解浮点数的存储格式。一个浮点数以32个二进制位表示,而这32位由其意义分为三段:1个符号位,如若是0则为正数,反之为负数;接下来的8位表示经过[偏移处理](这是为了使之能表示-127-128)后的指数;最后23位表示的则是[有效数字]中除最高位以外的其余数字。如图:

将上述结构表示成公式即为
其中偏移量$B=127$,$m$表示有效数字的尾数($0<m<1$),而指数$E-B$的值决定了有效数字(在Lomont和McEniry的论文中称为“尾数”(mantissa))代表的是小数还是整数。以上图为例,将描述代入有$m=1\times2^{-2}=0.250$),且$E-B=124-127=-3$,则可得其表示的浮点数为$x=(1+0.250)\cdot2^{-3}=0.15625$。
| 符号位 | |||||||||
| 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | = | 127 |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | = | 2 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | = | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | = | 0 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | = | −1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | = | −2 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | = | −127 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | = | −128 |
8位二进制整数补码示例
如上所述,一个有符号正整数在二进制补码系统中的表示中首位为0,而后面的各位则用于表示其数值。将浮点数取别名存储为整数时,该整数的数值即为$I=E\times 2^{23}+M$,其中E表示指数,M表示有效数字;若以上图为例,图中样例若作为浮点数看待有$E=124$,$M=1\cdot 2^{21}$,则易知其转化而得的整数型号数值为$I=124\times 2^{23} + 2^{21}$。由于平方根倒数函数仅能处理正数,因此浮点数的符号位(即如上的Si)必为0,而这就保证了转换所得的有符号整数也必为正数。以上转换就为后面的计算带来了可行性,之后的第一步操作(逻辑右移一位)即是使该数的长整形式被2所除。
魔术数字
对猜测平方根倒数速算法的最初构想来说,计算首次近似值所使用的常数0x5f3759df也是重要的线索。为确定程序员最初选此常数以近似求取平方根倒数的方法,Charles McEniry首先检验了在代码中选择任意常数R所求取出的首次近似值的精度。回想上一节关于整数和浮点数表示的比较:对于同样的32位二进制数字,若为浮点数表示时实际数值为$x=(1+m_x)2^{e_x}$,而若为整数表示时实际数值则为$I_x=E_xL+M_x$,其中$L=2^{n-1-b}$。以下等式引入了一些由指数和有效数字导出的新元素:
再继续看McEniry 2007里的进一步说明: $$ y=\frac{1}{\sqrt{x}} $$
对等式的两边取二进制对数($\log _{2}$,即函数$f(n)=2^{n}$的反函数,有
以如上方法,就能将浮点数x和y的相关指数消去,从而将乘方运算化为加法运算。而由于$\log_{2}{x}$ 与$\log2(x^{-1/2})$线性相关,因此在$x$与$y{0}$(即输入值与首次近似值)间就可以线性组合的方式创建方程。在此McEniry再度引入新数$\sigma$描述$\log {2}{(1+x)}$与近似值R间的误差:由于$0\leq x<1$,有$\log{2}(1+x)\approx x$,则在此可定义$\sigma $与x的关系为$\log {2}{(1+x)}\cong x+\sigma $,这一定义就能提供二进制对数的首次精度值(此处$0\leq \sigma \leq {\tfrac {1}{3}}$;当R为0x5f3759df时,有$\sigma =0.0450461875791687011756$。由此将$\log {2}{(1+x)}=x+\sigma$代入上式,有: $$ m_y+\sigma+e_y=-\frac{1}{2}m_x-\frac{1}{2}\sigma-\frac{1}{2}e_x $$
参照首段等式代入$M{x}$,$E{x}$,$B$与$L$,有:
移项整理得: $$ E_yL+M_y=\frac{3}{2}(B-\sigma)L-\frac{1}{2}(E_xL+M_x) $$
如上所述,对于以浮点规格存储的正浮点数x,若将其作为长整型表示则示值为$I{x}=E{x}L+M_{x}$,由此即可根据x的整数表示导出y(在此$y={\frac {1}{\sqrt {x}}}$,亦即x的平方根倒数的首次近似值)的整数表示值,也即: $$ I_y=E_yL+M_y=R-\frac{1}{2}(E_xL+M_x)=R-\frac{1}{2}I_x $$
最后导出的等式$I{y}=R-{\frac {1}{2}}I{x}$即与上节代码中i = 0x5f3759df - (i»1);一行相契合,由此可见,在平方根倒数速算法中,对浮点数进行一次移位操作与整数减法,就可以可靠地输出一个浮点数的对应近似值。到此为止,McEniry只证明了,在常数R的辅助下,可近似求取浮点数的平方根倒数,但仍未能确定代码中的R值的选取方法。
关于作一次移位与减法操作以使浮点数的指数被-2除的原理,Chris Lomont的论文中亦有个相对简单的解释:以$10000=10^{4}$为例,将其指数除-2可得$10000^{-1/2}=10^{-2}=1/100$;而由于浮点表示的指数有进行过偏移处理,所以指数的真实值e应为$e=E-127$,因此可知除法操作的实际结果为$-e/2+127$,这时用R(在此即为“魔术数字”0x5f3759df)减之即可使指数的最低有效数字转入有效数字域,之后重新转换为浮点数时,就能得到相当精确的平方根倒数近似值。在这里对常数R的选取亦有所讲究,若能选取一个好的R值,便可减少对指数进行除法与对有效数字域进行移位时可能产生的错误。基于这一标准,0xbe即是最合适的R值,而0xbe右移一位即可得到0x5f,这恰是魔术数字R的第一个字节。