概念
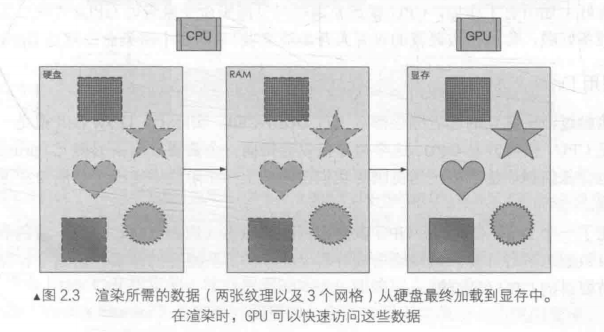
渲染流水线的工作任务是由一个三维场景出发、生成(或者说渲染)一张二维图像。 –冯乐乐《unity3d shader 入门精要》
这是一个比较标准的说法,因为不一定是渲染到显示器上,也有可能把渲染结果保存到一个Texture中,就是我们常说的RenderTarget。
阶段
渲染流水线可以分为三个阶段:应用阶段、几何阶段、光栅化阶段

-
应用阶段(CPU处理)
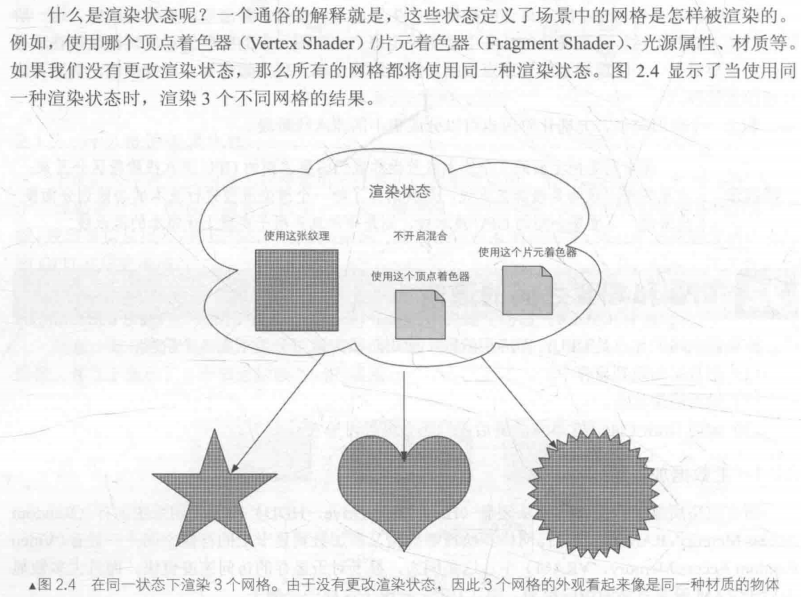
这一阶段开发者需要准备好场景数据,如摄相机位置、视锥体、模型和光源等,接着,还需要做粗粒度的剔除工作(把看不见的物体剔除) 最后,需要设置好每个模型的渲染状态(使用的材质、使用的纹理、使用的Shader等) 这一阶段最重要的输出是渲染所需的几何信息,即渲染图元(rendering primitives),渲染图元可以是点、线、三角面等。
-
几何阶段(GPU处理)
几何阶段主要用于处理所有和我们绘制的几何相关的事情。几何阶段负责和每个渲染图元打交道,进行逐顶点、逐多边形的操作。这个阶段可以进一步分成更小的流水线阶段。 几何阶段的一个重要任务就是把顶点坐标变换到屏幕空间中,再交给光栅器进行处理。 总结:输入的渲染图元->屏幕空间的二维顶点坐标、每个顶点对应深度、着色等信息
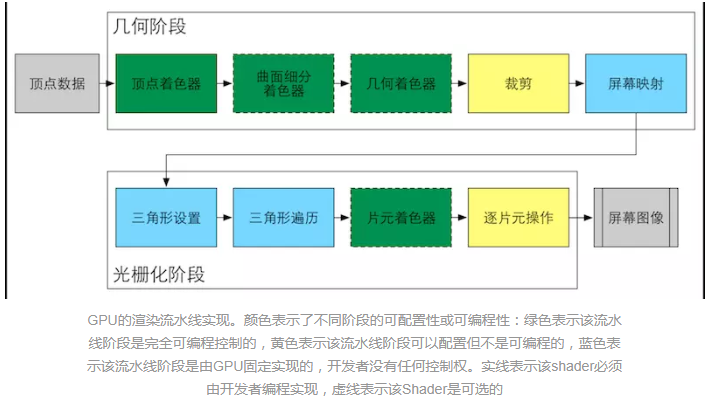
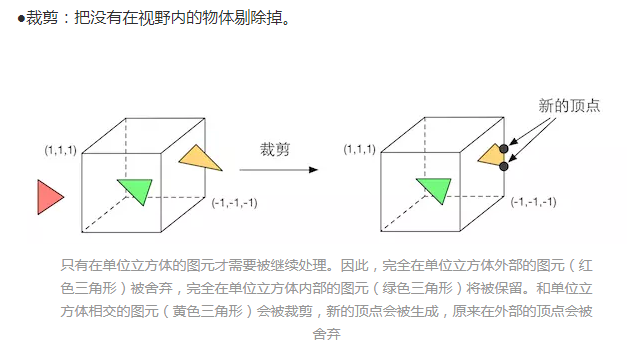
**注意,这里是裁剪(clipping),CPU里面有做剔除(culling) **
-
光栅化阶段(GPU处理)
将会使用上一个阶段传递的数据来产生屏幕上的像素,并渲染出最终的图像。主要任务是决定每个渲染图元中的哪些像素应该被绘制在屏幕上。
总结
### 1.OpenGL和DirectX
开发者直接访问GPU是一件非常麻烦的事情,可能需要与各种寄存器、显存打交道,而图像编程接口在这些硬件的基础上实现了一层抽象。
而OpenGL和DirectX就是这些图像应用编程接口,他们之间江湖恩怨,可以去看这篇文章。这些接口架起了上层应用程序与底层GPU的沟通桥梁。上层应用程序向这些接口渲染命令,而这些接口会依次向显示驱动发送渲染命令,而显卡驱动会把这些命令翻译成GPU能听懂的语言来让他们进行工作。
### 2.HLSL、GLSL和CG
这三个指的都是着色器的编程语言。
HLSL:High Level Shading Language,DirectX的着色器语言,由微软控制着色器的编译,就算使用了不同的硬件,其编译结果也是一样的,其使用的平台比较局限,几乎都是微软自己的产品,如Windows、Xbox 360等
GLSL:OpenGL Shading Language,OpenGL的着色器语言,优点在于其跨平台性,可以在Windows、Mac、Linux甚至移动平台使用,这种跨平台性是由于OpenGL没有提供着色器编译器,而是由显卡驱动来完成着色器的编译工作的。即只要显示驱动支持对GLSL的编译它就可以运行。
CG:C for Graphics,NVIDIA的着色器语言,实现了真正意义上的跨平台,它会根据平台不同,编译成相应的中间语言。
3.Draw Call
Draw Call本身的意义很简单,就是CPU调用图像编程接口。
1.CPU和GPU是如何实现并行工作的?
主要的解决方案是命令缓冲区,命令缓冲区包含了一个命令队列,由CPU向其中添加命令,而由GPU从中读取命令,添加和读取的过程是独立的。这样使得CPU和GPU可以相互独立工作。当CPU需要渲染对象时,则向命令缓冲区中添加命令,而当GPU完成上一次渲染任务后,它就可以从命令队列中取出一个命令并执行它。
2.为什么Draw Call多了会影响帧率?
在每次调用Draw Call之间,CPU需要向GPU发送很多内容,包括数据、状态和命令。CPU需要完成很多工作,例如检查渲染状态等。而一旦CPU完成了这些准备工作,GPU就可以开始本次的渲染。GPU渲染的速度是比较CPU提交指令的速度要快很多的。所以性能的瓶颈会出现在CPU身上,如果Draw Call的数量太多,CPU就会把大量的时间花费在提交Draw Call上,造成CPU过载。
3.如何减少Draw Call?
主要的解决方案是批处理(Batch),把众多小的合并Draw Call合并成一个Draw Call,当然不是所有情况都能合并的。我们可以对网格进行合并,但是合并的过程是比较消耗时间的,因此批处理技术更适合于静态的网格。
合并需要注意的点:
避免使用大量很小的网格,当不可避免的要使用这些这么小的网格时,考虑是否可以合并他们。
避免使用过多的材质,因为相同的材质会方便我们进行合并
4.什么是固定函数的流水线?
简称固定管线,通常是指在旧GPU上实现的渲染流水线。开发者没有对流水线完全控制权,只有一些配置操作,配置操作只有开和关